










Cut annotation costs
Automated speaker labeling replaces manual annotation workflows. Reduce human review time by a factor of ten.
Higher model accuracy downstream
Cleaner, well-segmented training data leads to measurable improvements on ASR, TTS, and speaker verification benchmarks.
Language-agnostic curation
Apply the same diarization pipeline to any language, any acoustic condition. One workflow for a global corpus.
Quality scoring built in
Confidence scores let you rank and prioritize the cleanest samples. Stop training on garbage you didn't know was there.
Use cases
Dataset curation: Automatically filter overlapping speech, background noise, and low-quality segments from large-scale audio corpora.
Speaker-level annotation: Generate per-speaker labels and timestamps at scale, replacing manual annotation.
Quality scoring: Use confidence scores to rank and prioritize clean samples, reducing the "garbage in, garbage out" problem.
Evaluation & benchmarking: Measure model output against speaker-attributed ground truth.
Voice agent evaluation: Quantify turn-taking, latency, and consistency in production voice agents
Features
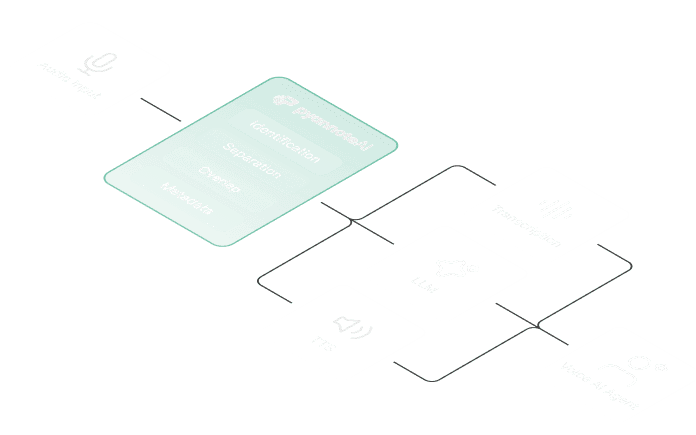
Speaker diarization
The same models cited in published research, with accurate results.
Voice activity detection
Strip silence, ambient noise, and non-speech regions.
Overlapping speech detection
Flag segments that would corrupt your training.
Confidence score
Surface which annotations to trust, which to drop.
pyannote.audio is the most-used speaker diarization libraries
Production-tested at corpus scale
Proven across major language families