Accuracy
Delivers high diarization performance with DER and speaker-attribution results.
Robustness
Stays consistent in noisy, overlapping, & multi-speakers conversations.
Speed
Processes full diarization and speaker-segmentation output in seconds.
What can go wrong?



Broadcast Interview - Radio interview speech.

Clinical - Clinical child assessment interviews.

Courtroom - Formal multi-speaker legal speech.

Conversational telephone speech - Two-speaker telephone conversations.
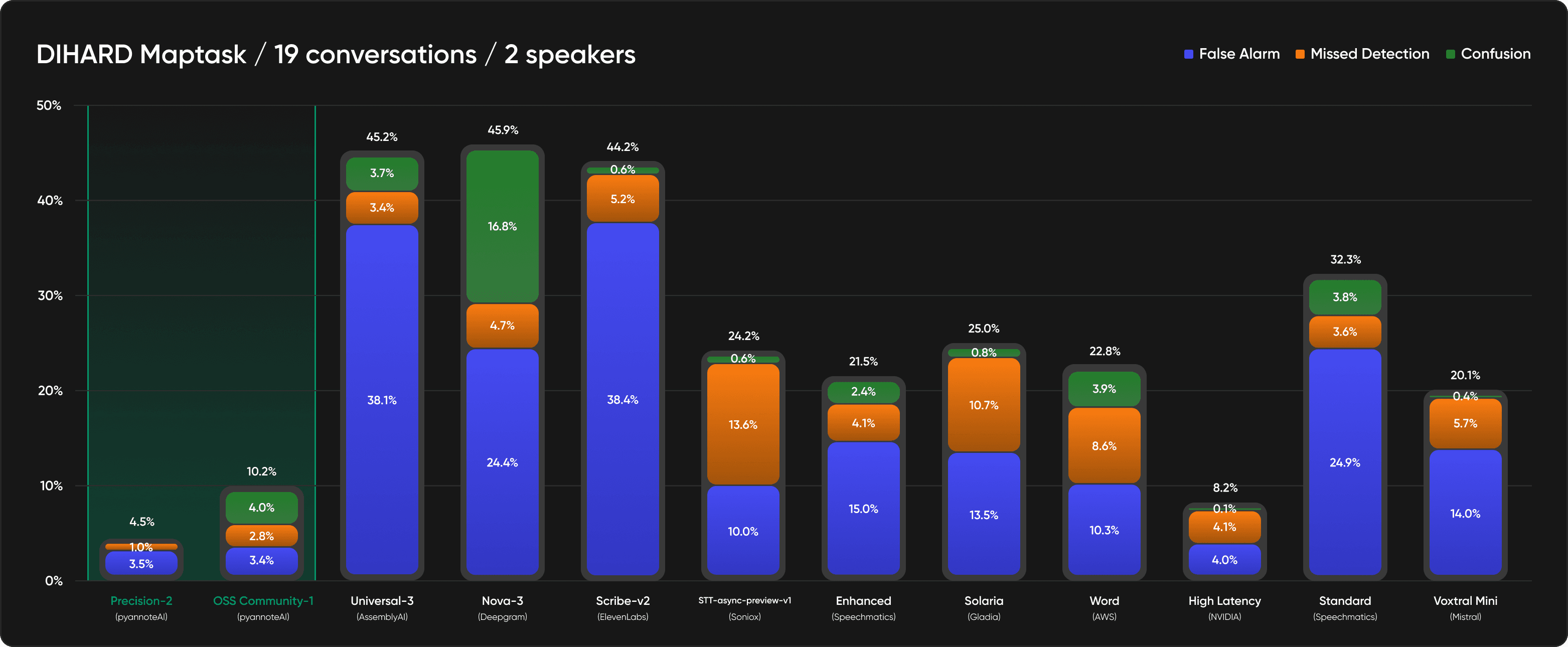
Map task - Task-oriented dyadic dialogue.

Meeting - Spontaneous multi-speaker meetings.

Restaurant - Noisy informal group conversations.

Sociolinguistic (field) - Field sociolinguistic interviews.

Sociolinguistic (lab) - Controlled sociolinguistic interviews.

Web video - Diverse online video speech.
DIHARD Broadcast
DIHARD Clinical
DIHARD Court
DIHARD CTS
DIHARD Maptask
DIHARD Meeting
DIHARD Restaurant
DIHARD Socio Field
DIHARD Socio Lab
DIHARD Webvideo
pyannoteAI - Precision-2
pyannoteAI - OSS Community-1
AssemblyAI - Universal-Pro-3
Deepgram - Nova-3
ElevenLabs - Scribe-v2
Soniox - STT-async-preview-v1
Speechmatics - Enhanced
OpenAI - GPT-4o-transcribe-diarize
AWS - Transcribe, word-level
NVIDIA - OSS NeMo streaming sortformer (very high latency)
