
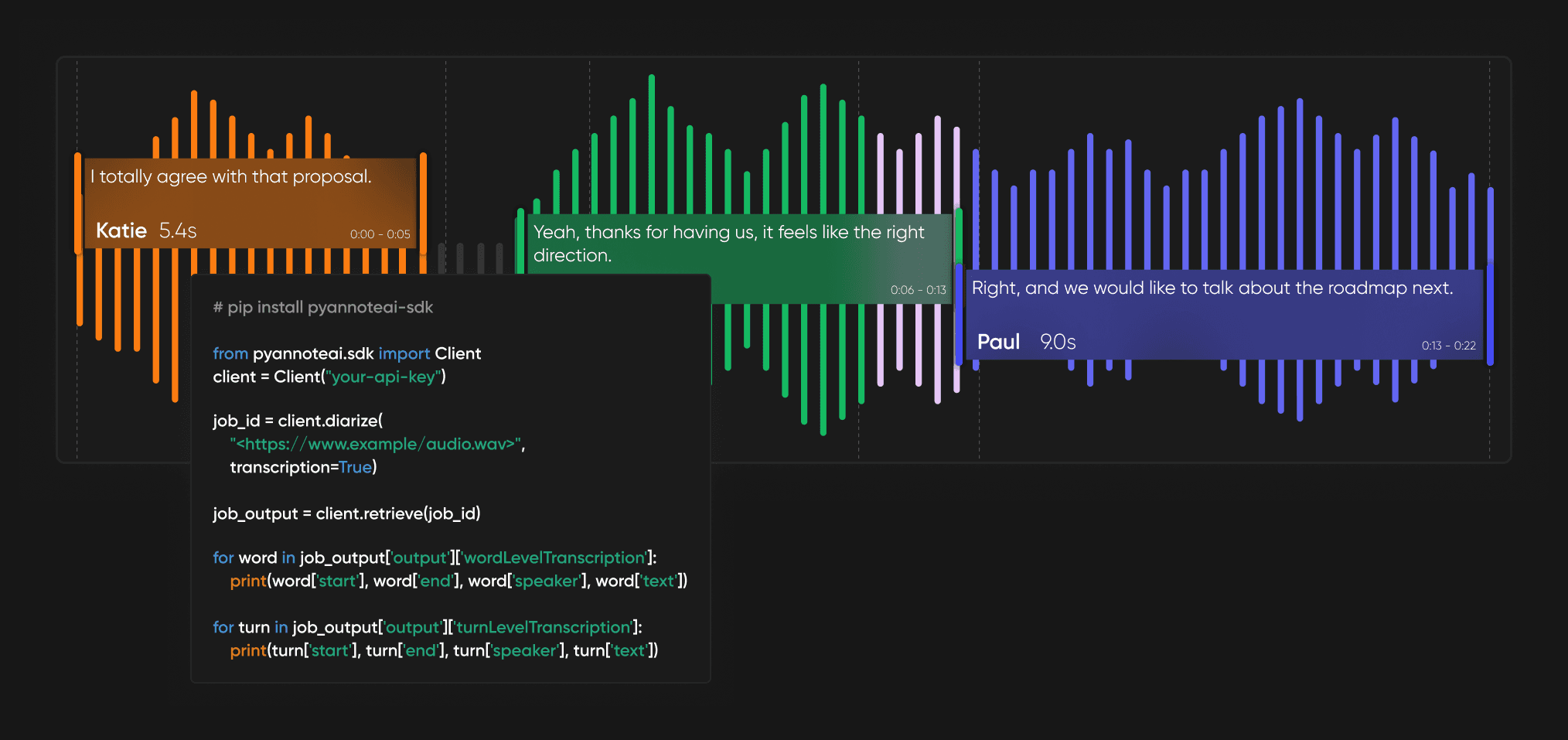








Get speaker-attributed transcription in one workflow
Associate timestamps directly with speaker-attributed text, improving synchronization between diarization and transcription.
Connect pyannoteAI models to any STT service
Bring your own transcription service. STT Orchestration adds pyannoteAI's most accurate speaker diarization to your preferred STT.
Reduce pipeline complexity and ambiguous segments
Automatically reconcile STT and diarization outputs, removing the need for separate forced alignment.
Save time and resources
Reduce timestamp reconciliation work, misattributed segments, and speaker identification errors.
Made for developers and Voice AI pipelines
Easy to integrate with existing workflows, our API is compatible with all tech stacks and protocols.
Deliver consistent results in any audio condition
Enhance conversation understanding in every scenario, our models maintain high accuracy results even in noisy, accented, or overlapping speech.
