










Streaming speaker intelligence at sub-300ms
Real-time diarization that delivers speaker metadata in time for your agent to act on it. Built for the latency budget production voice agents actually live with.
Multi-party conversation, handled
Track multiple speakers across a single conversation: primary user, background speakers, supervisors, family members, so your agent responds to the right person and ignores the rest.
End-of-thought detection
Know when the user has actually finished speaking, not just paused. Stop interrupting users mid-sentence and stop leaving them waiting in awkward silences.
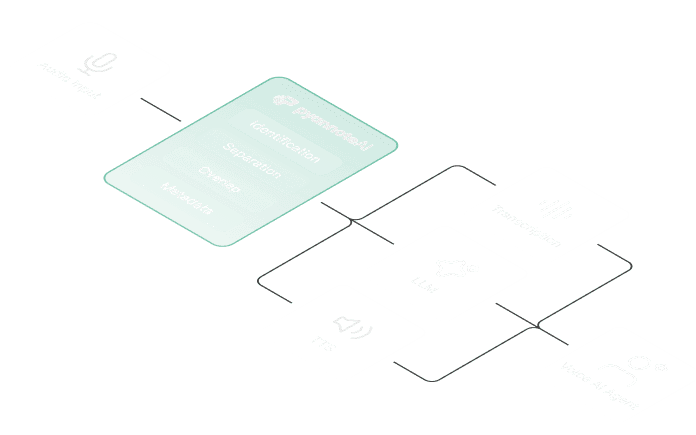
Plug into the frameworks you already use
Works alongside any conversational AI stack. We don't replace your agent framework, we add the speaker intelligence layer it's missing.
Use cases
24/7 customer support agents: Reliable speaker attribution so agents respond to the right caller, even when multiple voices share a line
Voice-powered admin automation: Multi-speaker meeting and dictation contexts handled cleanly, including supervisor handoffs and team-based workflows
Drive-thru and quick-service order agents: Filter out background speakers, ambient noise, and crosstalk so the agent only acts on the customer at the window
Voice agent evaluation & QA: Turn-taking metrics, speaker consistency, and interaction quality measurement for production agent fleets
Multi-party voice interfaces: Track multiple users in household, shared workspace, and group conversation contexts
Features
Streaming Diarization
Sub-300ms latency speaker attribution for live voice agents
Speaker diarization
Track who's speaking to maintain context across multi-party conversations
End-of-thought detection
Know when users have finished speaking, avoid interruptions and dead-air delays
Overlapping speech detection
Tag simultaneous speech and crosstalk so the agent acts on the right turn
streaming diarization latency
languages supported
10+ years
of academic research