Blog

"pyannoteAI diarization is the best, but integrating it with [your STT provider goes here] is painful."
If you're building voice AI systems, you know this workflow:
Use STT to transcribe speech into words (one line of code);
Run pyannoteAI diarization to identify speakers (one line of code);
Reconcile their outputs (hundreds of lines of spaghetti code)
The reconciliation step (matching timestamps, resolving ambiguous overlapping segments, and attributing words to speakers) is where pipelines break and errors compound.
We built STT orchestration to eliminate this entire class of problems. One API call delivers speaker-attributed transcription with perfect timestamps: no manual reconciliation required.
Why we built it?
Our mission at pyannoteAI is to deliver accurate insights about any conversation, regardless of audio quality. We've built the most accurate diarization models on the market because understanding who speaks when is foundational to conversation intelligence.
However, based on discussions with hundreds of companies, we identified two persistent gaps in voice AI workflows.
First, bundled diarization does not perform. Most commercial STT services include diarization as a feature, but it is never their main focus. Speech recognition is the core product; diarization is a checkbox. Teams that need accurate speaker attribution use pyannoteAI for diarization and a separate STT for transcription.
Second, reconciling outputs is error-prone. When you run diarization and transcription separately, you end up with a reconciliation problem. For instance, diarization provides you with an accurate speech turn boundary at time t while your STT returns words with slightly different timestamps t + 𝛿. And now, you are writing heuristics to match them: “If overlap exceeds 60%, attribute to that speaker; if ambiguous, apply fallback logic.” Every team solves this differently. Most solutions are brittle. All of them waste engineering time.
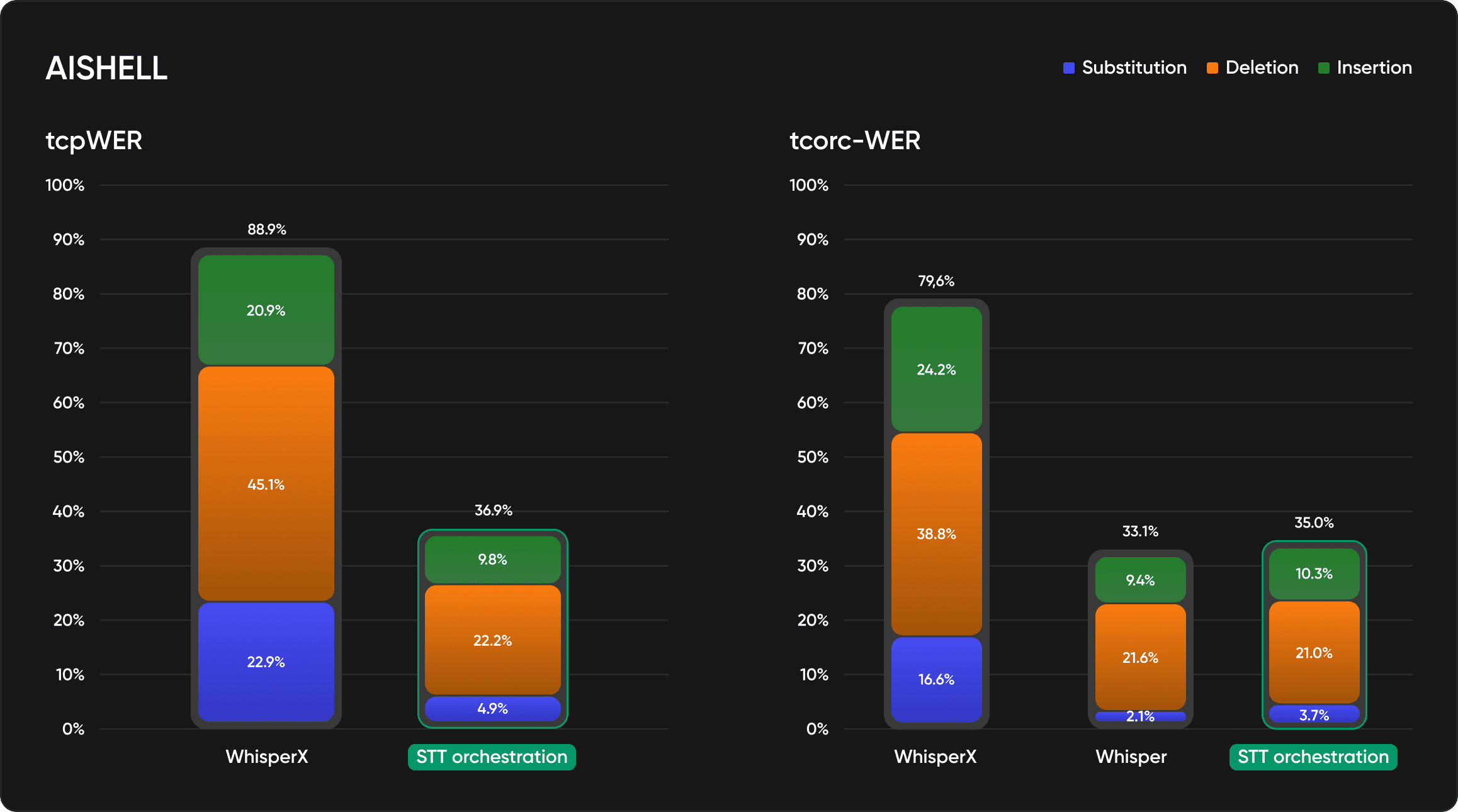
There comes STT orchestration, built to remove this reconciliation tax entirely. One API call handles both diarization and transcription, aligns their outputs, and delivers clean speaker-attributed transcripts. Our early benchmarks show significant (tcp)WER improvements compared to standard STT workflows, fewer attribution errors, fewer ambiguous segments, and better accuracy across diverse audio conditions.
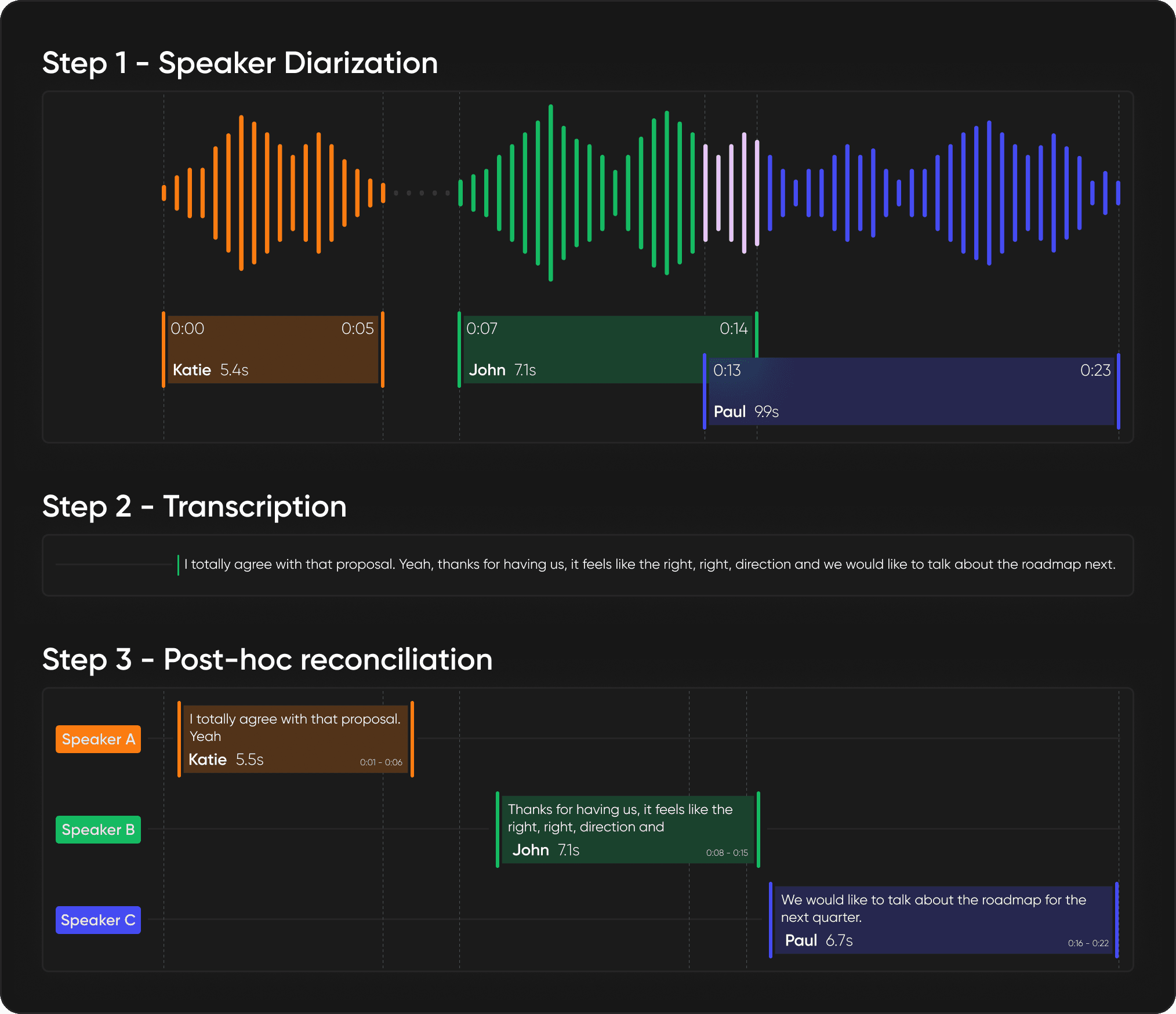
How it works
STT Orchestration is an orchestration layer that coordinates diarization and transcription in a unified pipeline. Instead of running two separate queries and manually matching their outputs, a single API call handles both processes and reconciles them automatically.
The workflow is straightforward:
Choose your diarization model: Precision-2 for production systems where accuracy is paramount, or Community-1 for less critical use (available in early 2026).
Select your transcription model: NeMo Parakeet (available today) or OpenAI Whisper (available in early 2026), with support for additional models coming later in 2026.
Send your audio: One API call to STT orchestration
Receive speaker-attributed transcription: Synchronized timestamps, clean speaker labels, ready for downstream tasks
Under the hood, STT orchestration relies on diarization to enhance the transcription and runs both models on your behalf. STT orchestration is much more than simple timestamp matching. You’ll enjoy both state-of-the-art attribution as well as enhanced transcription (usually translating into lower word error rates according to our benchmarks).
The output format is consistent regardless of which models you select, so your downstream code does not change when you upgrade diarization models or switch transcription providers.

Bring your own transcription
STT orchestration is built on a fundamental principle: you should not have to compromise on either diarization or transcription quality.
Most voice AI teams already have a transcription provider that works for their specific needs, whether that is a model fine-tuned for a specific domain vocabulary, a service optimized for particular accents and languages, or a commercial STT that fits their compliance requirements.
STT orchestration enhances your existing transcription setup with pyannoteAI's most accurate speaker diarization. You keep the transcription service you have chosen. We add the speaker intelligence layer that makes your transcripts actionable.
Currently supporting NeMo Parakeet, with Whisper coming in early 2026 and additional STT services rolling out throughout the year. The architecture is STT-agnostic; if you have a transcription service that works for you, we can enrich it with accurate speaker attribution.
Key benefits & use cases
Accurate speaker attribution in any audio condition. This is critical. Clean, studio-quality audio is rare in production systems as real-world voice AI deals with background noise, overlapping speech, multiple speakers, cross-talk, varying microphone quality, and acoustic interference. STT Orchestration is engineered for these conditions, the messy, unpredictable audio that defines actual conversations.
We did not build this for curated datasets. We built it for customer support calls where agents and customers talk over each other. For meeting recordings captured on laptop microphones with HVAC noise in the background. For field interviews conducted in busy environments. For any scenario where audio quality varies, and traditional transcription pipelines drown in errors.
Integrate any STT service without reconciliation overhead. You are no longer locked into bundled diarization. Use pyannoteAI for speaker attribution, the most accurate system available, and connect it to whatever transcription model works for your use case. Whether that is an open-source model that you have fine-tuned on domain-specific vocabulary, a commercial service optimized for your target language and accent distribution (soon), or a custom STT trained on proprietary data.
Reduce errors and eliminate manual cleanup. When you manually reconcile diarization and transcription, errors compound. Slight timestamp mismatches mean words are attributed to the wrong speaker. Ambiguous segments get dropped or duplicated. These mistakes propagate through your entire pipeline, into your conversation analytics, your LLM-generated summaries, and your downstream models. Reduce this class of errors by handling alignment algorithmically, using diarization to guide attribution decisions.
Ready for downstream tasks immediately. The output is what you actually use: speaker-attributed text with synchronized timestamps. Feed it directly into LLMs for summarization. Build conversation analytics without preprocessing. Generate meeting notes with proper speaker labels. Train custom models on correctly attributed data. No intermediate processing required.
Common use cases we are seeing:
Meeting intelligence platforms: Accurate speaker attribution for multi-participant meetings, even with crosstalk and interruptions.
Customer support analytics: Attribute sentiment and topics to agents vs. customers across thousands of calls.
Medical transcription: Separate doctor and patient speech in the examination room with background equipment noise.
Legal discovery: Identify speakers in depositions, hearings, and recorded conversations for case analysis.
Media production: Generate accurate transcripts or subtitles for podcasts and interviews with multiple hosts and guests.
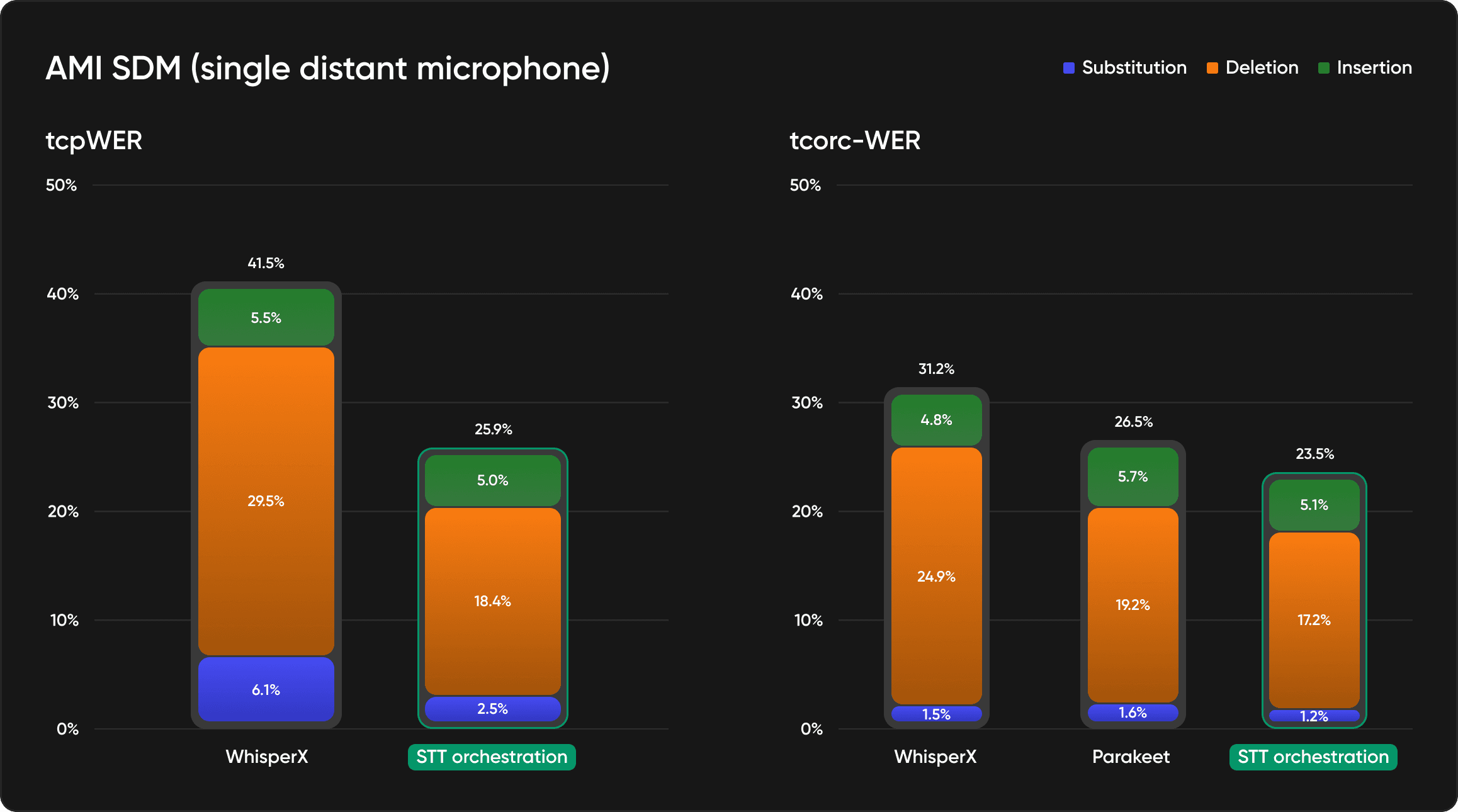
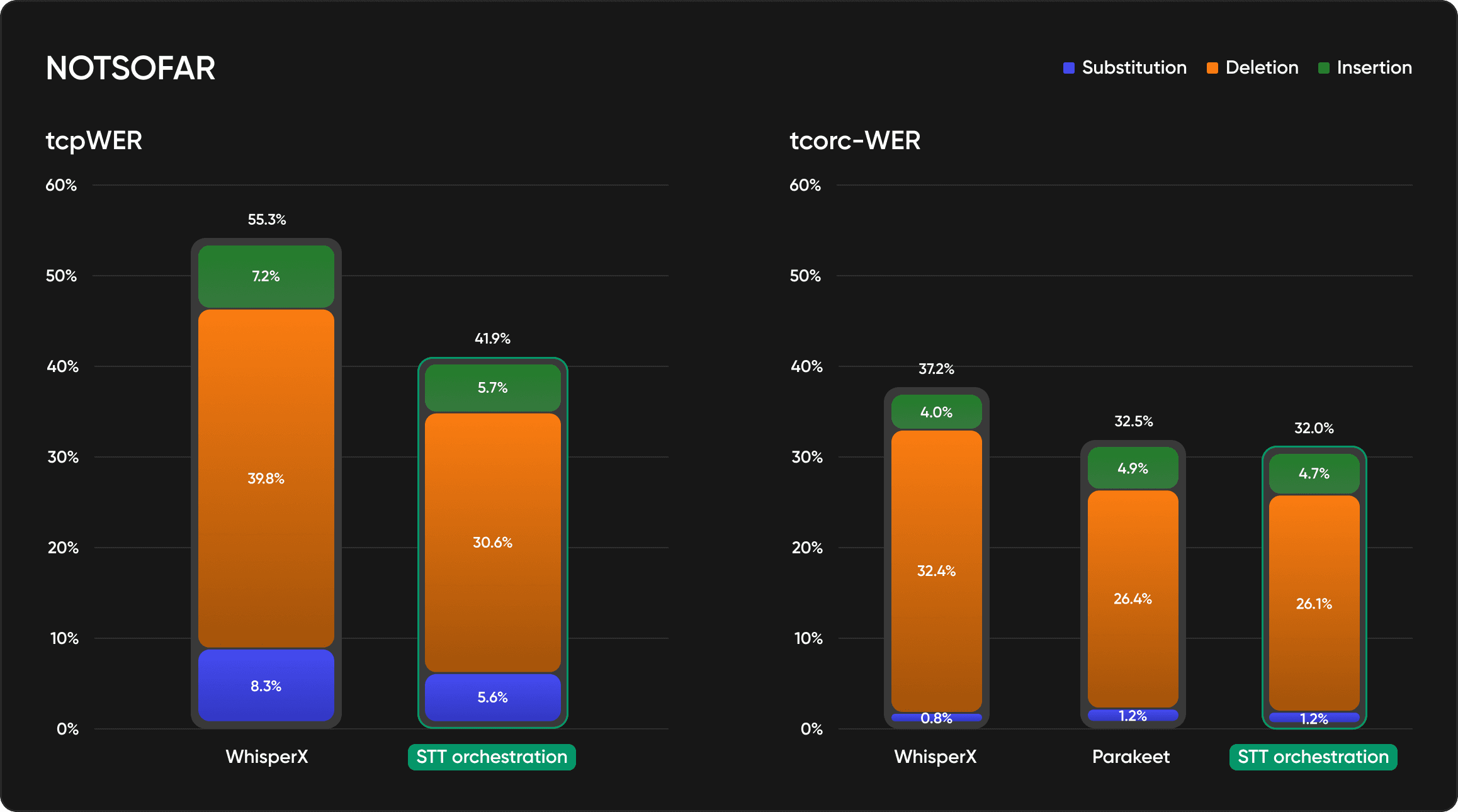
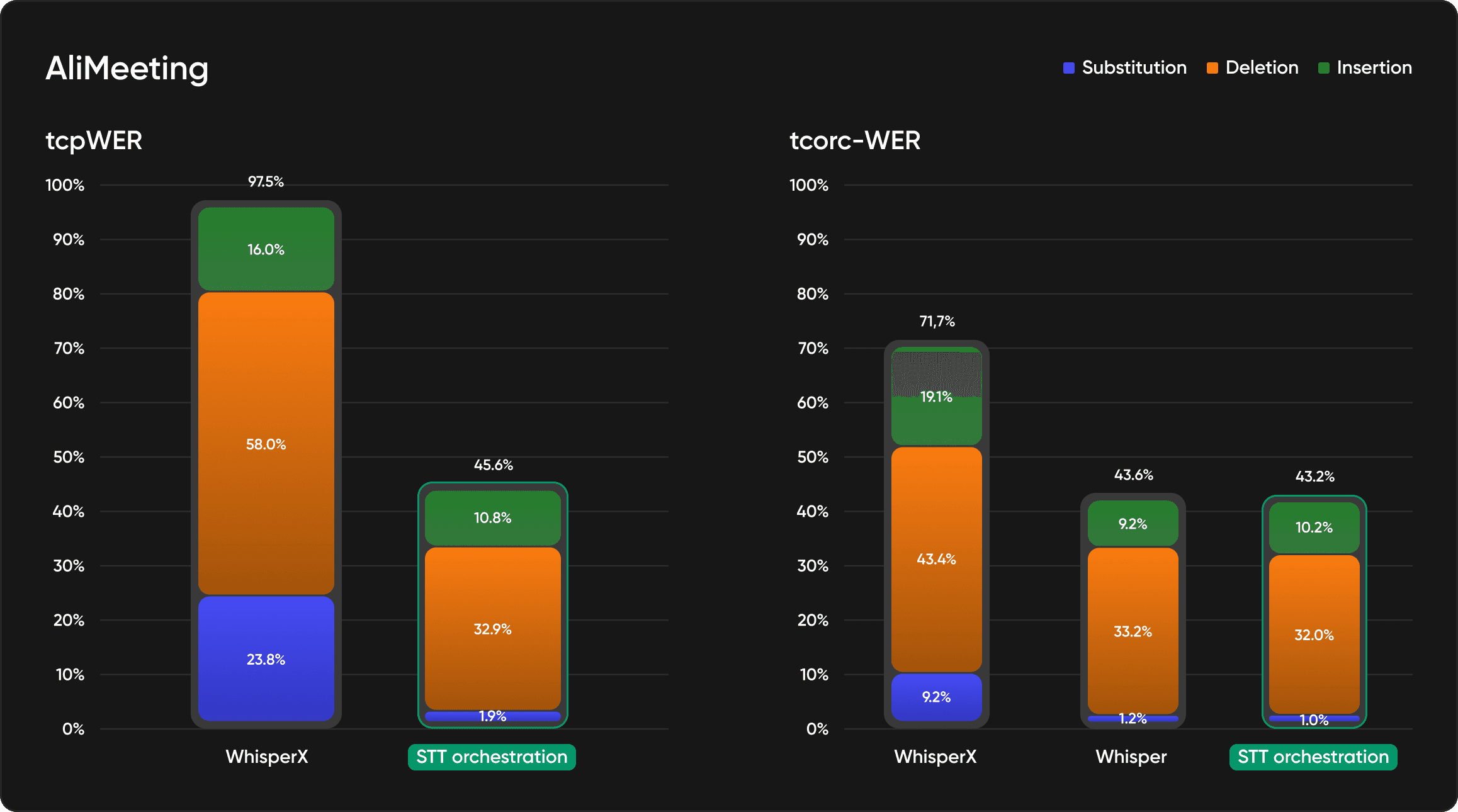
Performance metrics
STT Orchestration significantly improves tcpWER (a variant of word error rate that penalizes both transcription and speaker attribution errors) and tcorcWER (a variant of word error rate that penalizes both transcription and timestamps errors) compared to standard STT workflows. We are measuring this across diverse audio conditions, within scenarios that cause traditional pipelines to fail.
Preliminary benchmarks show:
Measurable reduction in speaker attribution errors
Fewer ambiguous segments requiring manual review
Better accuracy on overlapping speech and cross-talk
Consistent performance across varying audio quality
What matters: STT Orchestration does not just match timestamps; it also aligns them. It uses diarization boundaries to inform the transcription process, reducing attribution errors that compound across downstream tasks.
Getting started
If you're already using pyannoteAI, integration is straightforward. If you're not, this is a good entry point.
Example with pyannoteAI Python SDK
Documentation and resources:
Full API documentation: pyannote.ai/docs/stt-orchestration
Start building
STT Orchestration launches December 11th. If you are into voice AI systems, conversation analytics, meeting intelligence, customer support tools, medical transcription, or media production, this eliminates a major integration pain point.
One API call, your diarization and transcription are aligned automatically, and speaker-attributed transcripts are ready for downstream tasks.
Try STT_Orchestration now and unlock the most accurate speaker-attributed transcription to fuel your Voice AI Pipeline.
Read the docs: pyannote.ai/docs
Join our Discord community to share your use case with our Voice AI community.
The development of the STT Orchestration model was made possible through access to the HPC resources of IDRIS under the dynamic allocation 2025-AD011014274R2, granted by GENCI. The availability of this high-performance computing infrastructure allowed us to significantly improve both the model architecture and its training pipeline, directly contributing to the accuracy and robustness gains observed in our benchmarks. We gratefully acknowledge IDRIS for their support throughout this work.
