Blog

Understanding who said what in a conversation is as important as knowing what was said. In multi-speaker audio, whether meetings, interviews, podcasts, or call center recordings, context, accountability, and clarity all depend on accurately attributing speech to individual speakers. Speaker diarization solves this by automatically identifying and separating speakers in audio streams, transforming raw transcripts into structured, attributable conversations. That structure is what makes speech-to-text genuinely useful in real-world applications.
What is Speaker Diarization?
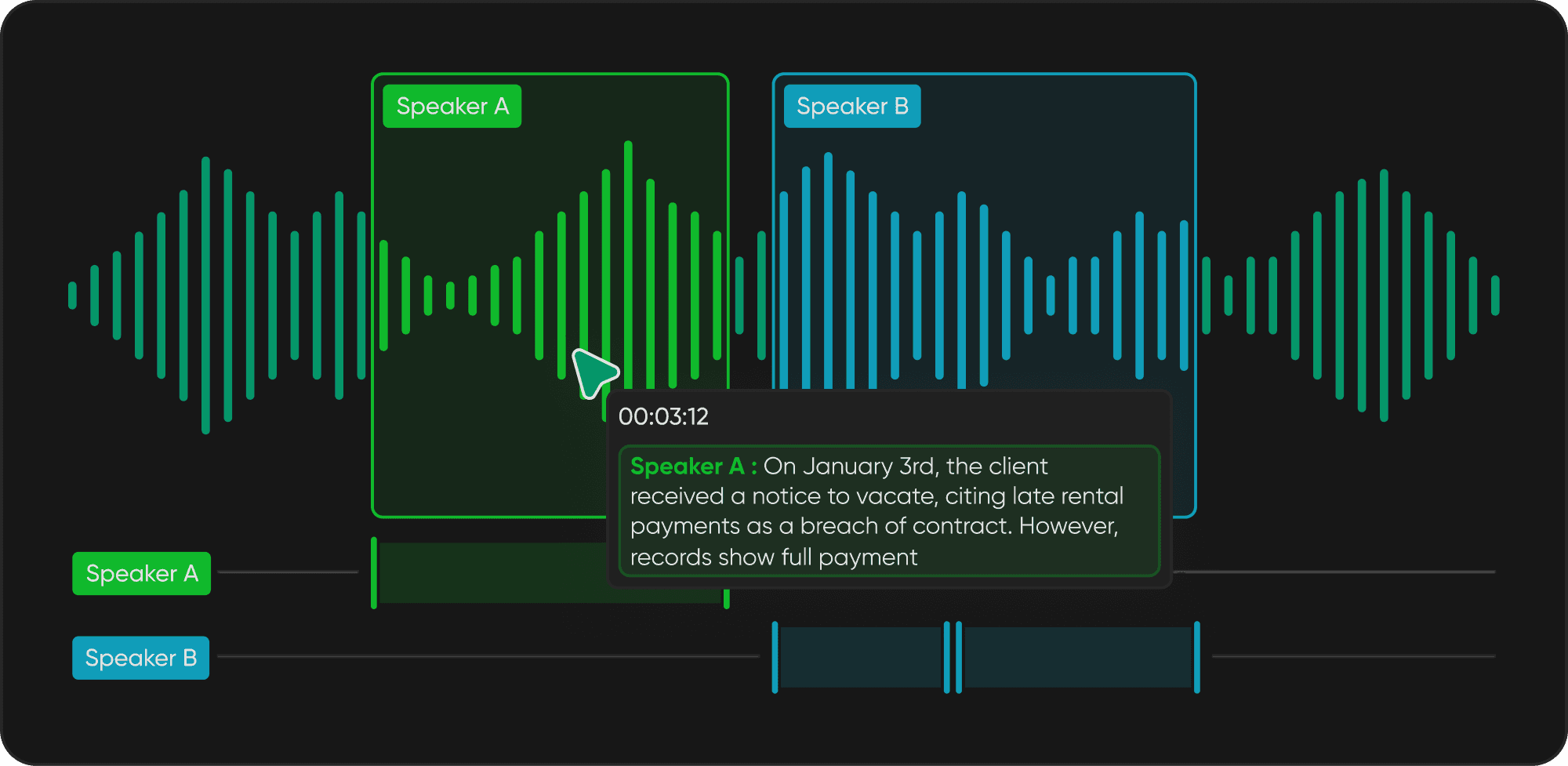
Speaker diarization is the process of automatically partitioning an audio recording to answer a fundamental question: "Who spoke when?" It transforms raw, multi-speaker audio into structured segments, each labeled with a unique speaker identity, turning overlapping conversation into an analyzable, speaker-attributed timeline.
In a world of hybrid meetings, fast-growing podcast libraries, and voice-first interfaces, understanding not just what was said but who said it has become mission-critical.
Speaker diarization serves as the foundational layer for conversation intelligence, enabling everything from accurate meeting transcription to call center analytics. Without robust diarization, multi-speaker audio stays an opaque stream of overlapping voices. With it, the structure and insights inside a conversation become accessible.
Speaker diarization vs. transcription
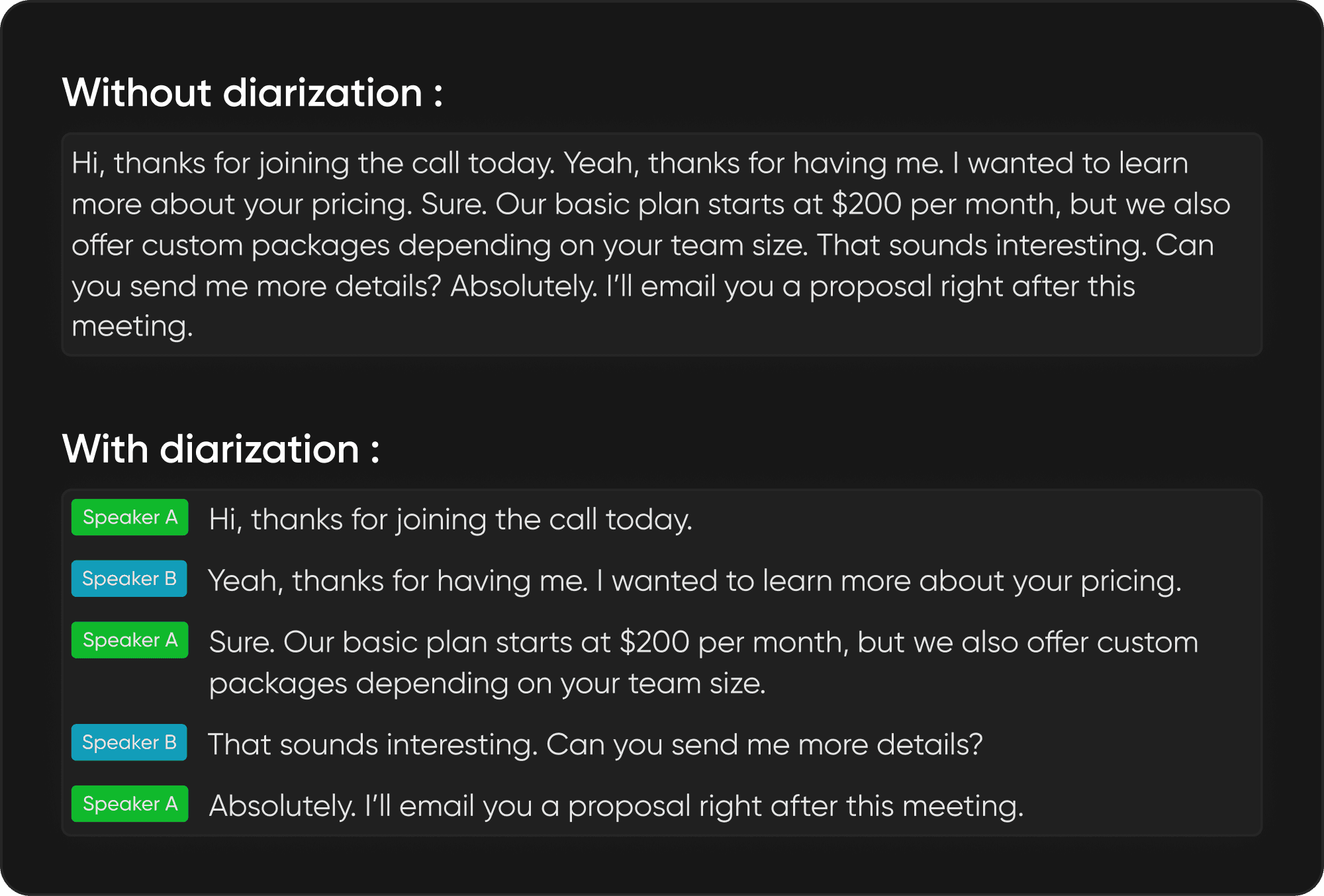
These two are often confused. Transcription (speech-to-text) converts spoken words into written text. Diarization determines who spoke each part. A transcript alone gives you a wall of words with no speaker boundaries. Diarization adds the structure that says "Speaker 1 said this, then Speaker 2 said that." Most production systems run them together: transcription for the words, diarization for the attribution. For a deeper look at why words alone fall short, see [[ FILL: internal link to "Why conversational context is the real performance driver" post ]].
Why speaker diarization matters in Audio and AI?
Conversations are becoming the most valuable unstructured data source for AI systems. Meetings, support calls, and consultations generate billions of hours of multi-speaker audio daily. Extracting intelligence from any of it depends on knowing who is speaking when.
Take a six-person meeting transcript. Without diarization, it is an unsearchable 10,000-word blob. With speaker labels, you can run per-speaker sentiment analysis, generate targeted summaries, extract action items, and flag compliance issues. Call centers separate agent and customer speech for QA. Healthcare teams rely on it for clinical documentation. Media companies cut manual speaker-tracking from hours to minutes.
The deeper leverage is downstream. Modern LLMs do strong work with conversational data when the input is structured. Strip out who said what and you lose context: who agreed, who pushed back, where decisions were made. Diarization is more than preprocessing. It is the foundational layer for conversational AI.
Accuracy drives user trust. Poor speaker attribution fragments transcripts, and users notice immediately. Clean diarization produces readable output, which is critical in meetings and customer service calls.
Better conversational AI performance. Diarization lets a system distinguish users from agents in real time, improving intent recognition and response quality. It is table stakes for virtual assistants and call center bots.
Lower infrastructure costs. Accurate speaker segmentation filters out silence and redundant speech, cutting GPU time and reducing compute waste across an inference pipeline.
Faster development cycles. Pre-trained diarization APIs and open-source models such as pyannote remove the need to build and maintain this capability from scratch, so teams focus on core features instead of foundational plumbing.
Enables downstream features. Diarization unlocks meeting summaries, action-item tracking, searchable speaker turns, and per-speaker analytics, and supports content indexing, sentiment analysis, and identity verification.
Want to see it on your own audio? Try the pyannoteAI playground or book a demo.
How does Speaker Diarization work?
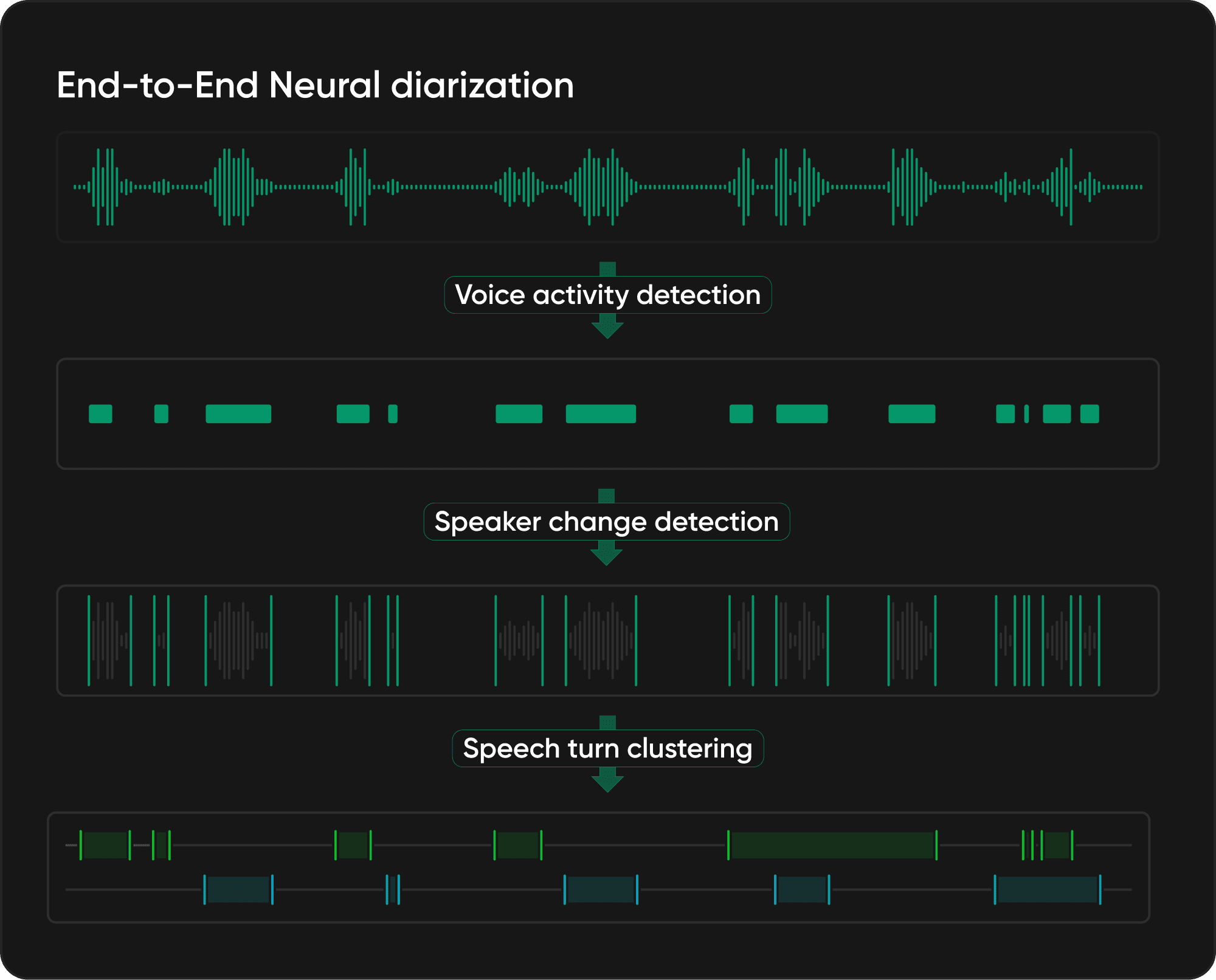
The modern diarization pipeline combines signal processing, machine learning, and algorithmic optimization. It breaks into four core stages that work together to segment speakers accurately.
1. Voice activity detection (VAD)
VAD identifies speech versus non-speech regions, filtering out silence, background noise, and non-verbal sounds so that compute focuses on actual speech. Modern VAD models use neural architectures trained on diverse data, handling everything from clean studio recordings to noisy field audio.
2. Segmentation or speaker change detection
This stage handles speaker turns, overlapping speech, and interruptions. It is critical for production systems, where raw outputs often contain spurious short segments or miss natural conversation boundaries. Segmentation uses both acoustic and temporal information to produce clean, usable results.
3. Speaker embeddings
Embeddings transform speech segments into high-dimensional vectors that capture unique vocal characteristics: pitch patterns, formant frequencies, and speaking style. These vectors act like vocal fingerprints, staying consistent regardless of content.
4. Clustering
The final stage groups embeddings to identify unique speakers without knowing the speaker count or identity upfront. This unsupervised problem requires algorithms that handle varying cluster sizes, overlapping distributions, and voice-similarity uncertainty. Hierarchical agglomerative clustering with learned similarity metrics determines the optimal number of speakers through threshold tuning.
pyannoteAI builds diarization models through iterative refinement based on real-world performance. Each iteration incorporates feedback from production deployments and expands training data to cover edge cases and challenging acoustic environments. For a hands-on build, see our Speech-to-text with speaker diarization tutorial.
Diarization vs. Speaker Identification vs. VAD
These tasks are related but fundamentally different. They often work together in production, and each serves a distinct purpose.
Task | Question it answers | Knows identities in advance? | Example |
|---|---|---|---|
Voice activity detection | "Is someone speaking?" | No | Marks where speech exists vs. silence |
Speaker diarization | "Who spoke when?" | No (assigns "Speaker 1", "Speaker 2") | Separates agent and customer on a call without names |
Speaker identification | "Which known speaker is this?" | Yes (requires pre-enrolled voice) | Labels a segment "This is John Smith" |
In practice they stack. Analyzing a board meeting recording, VAD first finds all speech segments and filters out silence and noise. Diarization then clusters those segments by speaker, building a timeline of when each member spoke. With pre-enrolled voice profiles, speaker identification can additionally attach real names. At pyannoteAI, the models are designed to excel at each task independently while staying compatible for integrated deployments.
How to evaluate speaker diarization quality?
Quick answer: The primary metric is Diarization Error Rate (DER), the fraction of audio time attributed to the wrong speaker (or missed entirely). Lower is better. On clean audio, strong systems reach low single-digit DER; on challenging benchmarks like DIHARD, state-of-the-art DER is meaningfully higher.

Measuring diarization quality requires metrics that capture different aspects of speaker attribution. The field relies on a few core measurements.
Diarization Error Rate (DER) is the primary metric, measuring the fraction of time incorrectly attributed to speakers. DER combines three error types:
Error type | What it means | Common cause |
|---|---|---|
Missed speech | A speaker is talking but the system detects no speech | Low-energy speech or conservative VAD thresholds |
False alarm speech | Non-speech (silence, noise, music) marked as speech | Overly permissive VAD or poor noise handling |
Speaker confusion | Speech detected but attributed to the wrong speaker | Embeddings not discriminative enough, or clustering fails to separate similar voices |
A DER of 5% means 95% of the audio duration is correctly attributed, though this does not map directly to word-level accuracy, since errors can cluster in specific segments. For current, dataset-by-dataset numbers across AMI, VoxConverse, and DIHARD, see the pyannoteAI benchmarks.
Speaker count accuracy measures how often the system correctly identifies the number of unique speakers. Clustering has to determine speaker count automatically, and getting it wrong (splitting one speaker into two, or merging two into one) cascades into higher confusion errors. Higher speaker-count accuracy tends to improve downstream tasks such as meeting summarization.
Robustness metrics evaluate performance across acoustic conditions: background noise, reverberation, overlapping speech, channel quality, and speaker similarity. A model can post low DER on clean audio yet degrade in noisy environments. Robustness testing uses controlled degradations (added noise at different signal-to-noise ratios, simulated reverberation, synthetic overlaps) to measure how gracefully performance holds up. Production systems need models that maintain acceptable DER across the full range of real-world conditions.
For a complete walkthrough of measuring diarization in your own pipeline, read How to evaluate Speaker Diarization performance.
Real-time and streaming speaker diarization
Some use cases need speaker labels as the audio arrives, not after the recording ends. Live captioning, voice agents, and real-time call analytics all require streaming diarization, which assigns speakers on a rolling basis with low latency. This is harder than batch processing, because the system cannot see the full recording before deciding who is speaking. pyannoteAI offers streaming speaker diarization built for these low-latency, multi-party scenarios.
Real-world applications of speaker diarization
The practical applications span industries, each with unique requirements that push the technology forward.
Meetings and conference calls
Knowing who said what matters for documentation, decision tracking, and accountability. Diarization enables automated summaries, speaker-behavior detection, and real-time meeting insights, making transcripts useful rather than just searchable.
Call centers and voice analytics
Diarization is table stakes for call analytics. Separating agent and customer speech supports CX metrics, compliance monitoring, and clean inputs for downstream analytics. High-confidence speaker labels keep QA pipelines and sentiment models reliable on edge cases.
Broadcast media and journalism
Clean speaker-labeled transcripts accelerate publishing. Diarization makes broadcast transcription efficient enough for closed captioning, archival indexing, and lip-sync workflows, turning manual editorial work into automated processing.
Healthcare transcription
Accurate attribution of doctor-patient dialogue matters for clinical documentation, diagnostics, and audits. Diarization tags the right speaker in medical transcripts, which is critical when records feed into care decisions or compliance reviews.
To go deeper, watch the talk by Hervé Bredin, co-founder of pyannoteAI and a specialist in diarization: JSALT 2025 Plenary, Speaker diarization, a (love) loss story.
How pyannoteAI performs
pyannoteAI maintains both an open-source lineage and a commercial platform. The open-source Community-1 model gives developers state-of-the-art diarization to self-host, while the commercial Precision-2 model targets the highest accuracy with enterprise reliability and support through the API.
[[ FILL: insert 2 or 3 verified, current numbers from the benchmarks page, e.g. "Precision-2 reaches X% DER on VoxConverse and Y% on DIHARD, an N% relative improvement over [comparison]." Do not publish without real figures. ]]
See the full, current results across standard datasets on the pyannoteAI benchmarks page. For guidance on choosing between self-hosting and the API, read [[ FILL: internal link to "Open Source vs API" post ]].
Key takeaways
Speaker diarization has moved from academic curiosity to an essential part of modern speech processing. By determining "who spoke when," it turns unstructured audio into actionable intelligence and enables applications that were impractical a few years ago. Accurate speaker attribution is also the key to understanding human communication at scale.
pyannoteAI is focused on pushing the boundaries of diarization while keeping the technology accessible to developers, researchers, and organizations. The open-source tools democratize access to state-of-the-art models, and the commercial platform delivers enterprise-grade performance, reliability, and support. Success shows up not only in benchmark scores but in real-world impact, from improving patient care to making content more accessible.
Explore the open-source Community-1 model or the commercial APIs to bring state-of-the-art diarization to your applications.
Frequently asked questions
Is speaker diarization the same as transcription?
No. Transcription converts speech into text. Diarization determines who spoke each part. They are usually combined: transcription for the words, diarization for speaker attribution.
How accurate is speaker diarization?
Accuracy is measured by Diarization Error Rate (DER), the fraction of audio time attributed incorrectly. Lower is better. Strong systems reach low single-digit DER on clean audio, with higher DER on challenging real-world benchmarks. See the pyannoteAI benchmarks for current figures.
What is a good Diarization Error Rate (DER)?
On clean, well-separated audio, single-digit DER is achievable. On noisy or overlapping multi-speaker audio, DER rises. The right target depends on the dataset and conditions, so compare numbers on similar audio to your use case.
Can speaker diarization run in real time?
Yes. Streaming diarization assigns speakers on a rolling basis with low latency, which is what live captioning and voice agents need. pyannoteAI provides streaming diarization for these scenarios.
How many speakers can diarization detect?
Modern systems determine the number of speakers automatically through clustering, without being told the count in advance. Accuracy depends on audio quality and how distinct the voices are.
Is pyannote free?
The open-source Community-1 model is free to self-host. The commercial Precision-2 model is available through the pyannoteAI API with enterprise performance and support.
